On Jun 27, China’s tech media Leiphone has published an exclusive interview with the co-founder of DxChain Allan Zhang, talking about the original intention and the conception of DxChain. Please refer down below for this interview.
Fueled by the revolutionary blockchain technology, the world today is entering a new era of internet where data has become the core resource for companies. Tech behemoths such as Amazon, Microsoft, and China’s BAT (Baidu, Alibaba, Tencent) have started a battle for the control of data. Meanwhile, many blockchain startups are beginning to tap into the promising market of Blockchain storage.
DxChain, a young Silicon Valley-based company, is one of these blockchain startups put the primary focus on data storage, computation, and data privacy. It is aimed to build a decentralized big data storage and machine learning network. Says DxChain co-Founder Liang (Allan) Zhang, DxChain’s mission is to leverage and monetize data.
Origins
Five years ago, Zhang founded an information security company called Trustlook. Zhang tells Leiphone that there are currently more than 500 million mobile users using Trustlook’s antivirus engine.

When Trustlook was growing its business in 2016, Zhang decided to apply artificial intelligence technologies to the antivirus engine. It was a right decision for the company because, in the second half of 2016, AI started to heat up.
However, Trustlook, an AI-powered information security company that provides antivirus engines and ransomware detection software, is highly dependent on sample data collected from its clients and partners. It comes up with two issues:
- Trustlook faces challenges to obtain high-quality sample data. For example, to get the patient’s DNA data, startups like Trustlook have to buy or trade data with large security vendors like Mcafee, Symantec, and Google. The subscription fee is obviously a burden.
- Trustlook cannot afford the cost of maintaining large machine learning clusters and data center storages. Says Zhang, the company has collected several petabytes of data (1PB: Petabyte terabytes = 1024TB), which will cost big budgets and resources for maintenance.
“So, we have been thinking about whether there is a way to save Trustlook’s resource costs and reduce the cost of storage and computation for business intelligence analysis. If we can reduce the cost by three percent to five percent, Trustlook will be very profitable,” says Zhang.
During this period, blockchain emerged as a distributed ledger network featuring decentralization, multi-nodes, and distributed storage. It offers an excellent solution: not just can it lower the cost of data extraction, it can also ensure the data will not be lost or tampered. By combining machine learning algorithms and big data analysis, the blockchain technology might help Trustlook break through the limits.
“Chains-on-chain” + big data analysis + machine learning
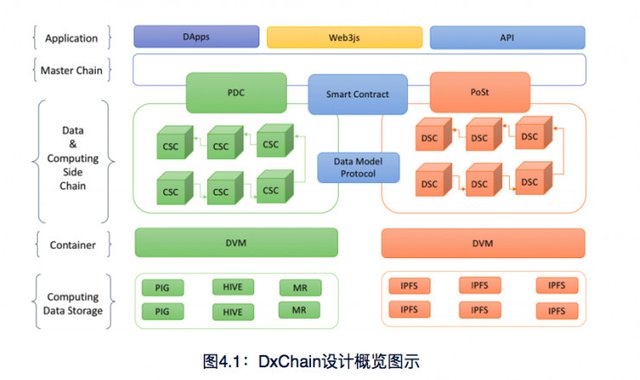
The network brings four innovations: a new decentralized computing architecture called “chains-on-chain” that orchestrates one master chain and two side chains; the Hadoop architecture incorporated to DxChain Network to facilitate big data processing and machine learning; a dedicated design to support data exchange and data analysis for most businesses.
Zhang believes the groundwork of internet — from mobile internet to internet of things — lies in big data computing. The future world is going to be built upon a value internet, which can store enough data and have capacities of data computing.
“However, the blockchain itself has limited storage space and is still in a very early stage, which restrains the future development of the value internet to a certain extent,” Zhang tells Leiphone.
During its early days, DxChain created “chains-on-chain” design, an architecture with one master chain and two side chains for data storage and computation.
Explicitly, the data side chain can store useful and valuable metadata to expand its capacity for indefinite storage; the computation chain can enable rapid search and parallel computing in large volumes of data; the master chain manages transaction-related operations while coordinates data chain and computation chain.
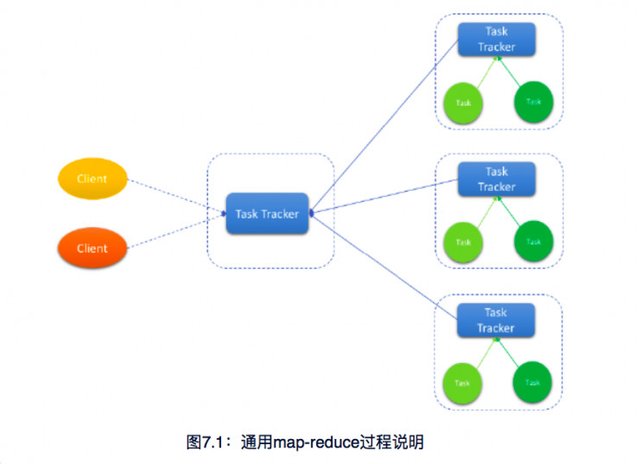
Imagine there are a large number of songs stored on the chain and handed over to every miner. To count these songs by numbers, average length, songwriters, etc., DxChain uses Map-reduce with a distributed computing logic to split the task. Under Map-reduce, the first step is to split data by labels such as regions and singers. The next step is to make a combinatorial counting between different regions. Finally, DxChain will divide the task of data storage and computation.
In this process, DxChain will split data, distribute data to each node, and assemble data between two or more nodes. The method of the congregation is called “reduce,” and the process of splitting and computation is called “map.” That is being said DxChain can split any complex computation to increase its computational efficiency linearly.
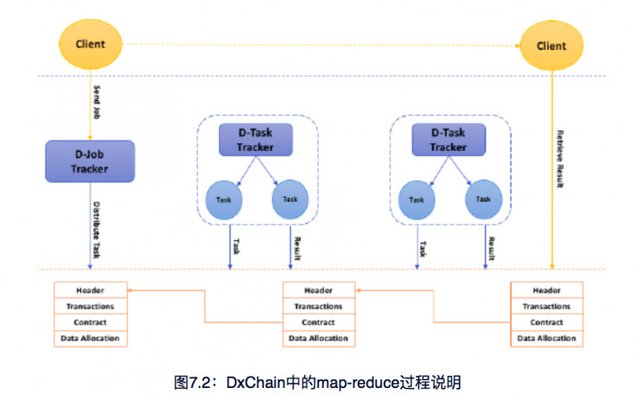
Says Zhang, DxChain redefines the Hadoop system and moves the tasks of Map-reduce to the chain. The decentralized system of Map-reduce manages tasks on the different nodes while communicating with the Hadoop job tracker. The combined advantages of these two systems achieve distributed computing in huge amounts of data across enterprises and industries.
Chain Storage, make the Blockchain world different
Zhang understands that any new technology needs to be implemented within a business scenario; otherwise it does not create any values. Therefore, he suggested that DxChain’s chains-on-chain design can be used to solve Trustlooks’s storage and computation problems. He decided to let Trustlook be the first company that puts data in DxChain’s blockchains.
Says Zhang, Trustlook has more than 500 million mobile users while its servers receive nearly three billion API requests per month. With so many terminals, each of which has so much data, if users and buyers, particularly enterprises, are willing to exchange data at reasonable prices in smart contracts, DxChain, as a third-party platform, can receive some of the proceeds as benefits. This will meet the interests of different groups.
For example, DNA data in the U.S. and Europe is highly valuable. Although many scientists have professional knowledges, their research is sometimes held back because they cannot access data. In this case, DxChain can somehow solve the problem and help scientists facilitate further progress.
Imagine a patient is willing to give his/her medical data to a scientist, or a data research company, or other institutes which have a demand. Once the data is stored on the chain, it can be simultaneously transferred to multiple agencies in the same blockchain. In this way, not only can the patient harvest a significant amount of income (to offset the expenses on medical treatments), but the seller can further reduce the cost and realize decentralization of the transaction.
However, implementing this technology is not easy. The consensus mechanism is often the most difficult one to be verified for any chain. Considering the difficulties to create and manage one chain, DxChain indeed faces challenges to built up its “chains-on-chain” structure and even add applications on it. “DxChain can’t achieve this goal in one step. We have to take step by step. We have to stabilize the master chain first, stabilize the first side chain, and form a solid structure between these two chains. Then we can talk about adding the third chain.”
The distributed storage market is more than just DxChain. Blockchain projects such as IPFS, Storj, SiaCoin, and Lisk (application chain) also make commitments to blockchain storage. For example, Lisk uses a structure of one master chain and one side chain to solve the problem of scaling and transaction speed. DxChain puts focus on data, while Lisk expands on distributed computing based on ledgers and transactions.
From Zhang’s perspective, DxChain is not limited to expanding ledgers or ramping up the transaction speed. Its goal is to pull up the blockchain to the same level of the current internet. “We are aimed to achieve blockchain storage, data and blockchain computing for real. Both will make huge contributions to the blockchain world.”
To achieve this goal, DxChain expects to launch the first version of the product demo at the end of June this year. Zhang tells Leiphone that “We will open source when the master chain is ready, and release some of the product demos to look at the stability of data storage in an internal test network.”
Conclusion
After a brief exchange, you can feel that Zhang has a passion for the future blockchain world. He once said:
One coin is a world, and one chain is a universe.
Zhang says that at this stage, each public chain is a “small world” while each blockchain is a “small universe.” Today, different “worlds” and “universes” are isolated, and they should be connected to each other.
Zhang indicated that many chains today can’t store their own data, and finds it is inappropriate to store data in a centralized organization or enterprise such as AWS or Baidu Cloud. Zhang hopes that DxChain will become a decentralized storage center in the future blockchain world. “When any data in a chain cannot be stored, it can be placed on the DxChain’s chain.”
In the future, it may be that thousands of chains will become interconnected and create a harmonious new world. At the same time, it might bring along many other problems, such as security, computations, transactions, etc. However, Zhang believes distributed problems should be solved in a distributed way. “We can break through one point at a time, one problem and another, and slowly turn these centralized things into decentralized.”