The rise of blockchain technology has reinvented the mode of value exchange on the Internet. Thereby came the term Internet of Value.
The value of the Internet, however, has been confirmed long before the birth of blockchain. Companies like Google and Facebook have made a huge amount of money from the information they obtained via the Internet, while the mass of Internet users who actually produced that information could only sit by and watch.
Imagine that we broke the big companies’ monopoly on information. Every user of the Internet would be able to fully utilize and evaluate his or her own data, without worrying about their privacy being invaded. Blockchain, which is decentralized by design, is supposed to be the perfect tool to realize that vision.
However, so far we see no way to bring that vision into reality within the framework of current technologies. Not even blockchain’s two most successful applications, namely Ethereum and Bitcoin, could achieve that goal.
Based on years of research, we believe that to fully realize the Internet of Value, we must bring big data onto blockchain. And to achieve that, the computation and storage capability of the blockchain must be expanded to match the volume of the whole Internet.
If we define the model of Google and Facebook as the Internet of Value 1.0, that of Bitcoin and Ethereum as the Internet of Value 2.0, Internet of Value 3.0 should be one that decentralizes the storage and usage of information for the whole online world.

Internet of Value 1.0 and 2.0
In the world of Internet of Value 1.0, information giants like Google and Facebook sit on lucrative revenue streams. Within the first quarter of 2018, both of them earned over ten billion dollars from advertising. Most of their revenue comes from user information, while their users get nothing from that information.
In 2008, a mysterious programmer Satoshi Nakamoto circulated a paper on a cryptography mailing list, titled “Bitcoin: A Peer-to-Peer Electronic Cash System”. This article outlined a clever system within which a safe and distributed database, namely blockchain, can be created. The system does not require an authority to oversee and testify the authenticity of data. Instead, it establishes an incentive mechanism, where the act of maintaining the distributed ledger will be rewarded with Bitcoin.
That paper, with its innovation in both technology and economy, marked the beginning of Internet of Value 2.0. Five years later, the invention of Ethereum introduced smart contracts into blockchain. It uses code to replace traditional third-party finance agents, thus bringing fundamental changes to fundraising.
However, the data processing capability of Bitcoin or Ethereum ledger is very inadequate compared to the current volume of the Internet. So far their applications have been limited to areas such as account transferring and logistic information tracing, as they could only handle that much data.

In sight of the above issues, we believe that we must break the bottleneck of data storage and computation on the blockchain before we could make any real changes to the current Internet.
The Internet of Value 3.0
Nakamoto’s most brilliant idea was PoW (Proof of Work), an incentive mechanism that reward miners according to their effective work. It lays the technological ground for the new blockchain economic model.
However, Nakamoto’s consensus protocol assigns most of the computing power to maintain the blockchain itself, so the computing power of the system is severely limited.
To resolve the limitations of PoW’s high latency and low throughput, more consensus and technologies emerged. For example, dPoS (delegated Proof of Stake) partially introduces centrality with super-nodes and off-chain brings high-frequency transactions to the side chain.
Some new chains also came out. Plasma developed another type of chain based on these concepts. The problem is that Plasma still focused on processing transactions. Morpheo also created a platform to support machine learning, but the design itself is centralized. The industry hasn’t yet to see a single satisfactory solution to provide a decentralized parallel computing environment that supports big data and machine learning.
DxChain’s design aims to build a platform for decentralized, autonomous big data exchange. The platform composed of countless personal computers or specially designed mining rigs, so that the cost of data storage and computation can be maintained at a very low level. As the data is not monopolized by some large corporation, its value will be evenly distributed to all of its owners.
1. Architectural Innovation
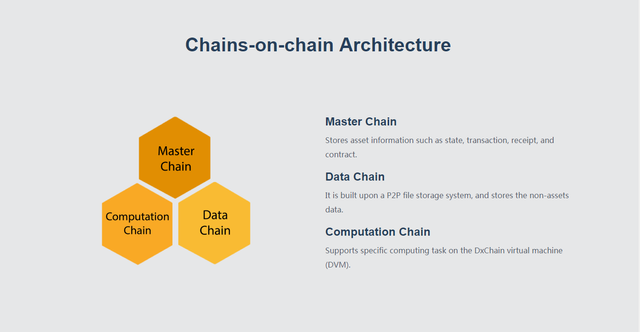
The system consists of three chains, one main computing chain and two side chains. One of the two side-chains will be running parallel computing to solve the problem of general-purpose computing for big data. It will eventually achieve machine learning and provides BI support. The other side-chain is mainly responsible for providing big data storage. It also provides corresponding support for the computation chain.
The main chain is responsible for providing transaction-related operations while coordinating these two sides chains.
2. Architectural Reference
It should be emphasized that our model refers to the Hadoop architecture.
Over the past decade, Hadoop has been the best solution for distributed storage of data within an organization or company. However, the problem of how to achieve trust between different organizations and participants in order to realize distributed storage is unable to be resolved by Hadoop. Yet Blockchain provides the perfect solution.
We have taken the technological advantages of Hadoop, which are repeatedly verified in the industry over the past decade, to combine with the unique mechanisms of blockchain to solve the distributed storage and computation issues in the center environment.
We hope that our public chain will be the future Hadoop in the Blockchain era — providing the most stable and universal solution for distributed storage and computation.
3. Detailed Innovation
From the technical details point of view, DxChain has three major innovations:
• The consensus mechanism under the computational framework adopts the “Verification game + Provable Data Computation (PDC)” mechanism, in which the Verification game guarantees the verifiability of the computation process, and the PDC ensures the verifiability of the computation results.
• The consensus mechanism of DxChain’s data storage utilizes the “Proof of Spacetime (PoSt) + Provable Data Possession (PDP)” mechanism to verify that miners continuously provide storage.
• DxChain’s data model is built upon storage and provides meaning for the data. Data thus becomes valuable knowledge and data calculations become convenient. In addition, the data model also helps to achieve data-model based encryption and two privacy protection mechanisms of differential-privacy.
As DxChain is able to collect and restore masses of individual data, each piece of data will be given more value as well as stronger privacy protection. In a secured privacy environment, individuals will be able to exchange their own data according to their wish, and benefit from it.
For example, in the medical field, patient information is usually a sensitive issue. Research institutes and pharmaceutical companies need patients’ data to conduct research, yet they can hardly get enough data due to privacy concerns. Project Dr. Watson has required IBM to work with hospitals to obtain patient data, but the progress has been difficult and slow.
On the other hand, patients can hardly benefit from their own data, as individual data has no value.

We believe that in the future, DxChain will be able to break the information monopoly of giant companies, thus bringing the Internet into a new, multi-dimensional and multi-polarizing era. That is the Internet of Value 3.0 we envision.